합성곱 신경망 기초 4(가중치 초기화, Weight Initialization)
CNN 강좌는 여러 절로 구성되어 있습니다.
- 합성곱 신경망 기초(CNN, Convolution Neural Network)
- 합성곱 신경망 기초 2(역전파, Backpropagation)
- 합성곱 신경망 기초 3(배치정규화, Batch Normalization)
- 합성곱 신경망 기초 4(가중치 초기화, Weight Initialization)
- 합성곱 신경망 기초 5(VGGNet, Very Deep Convolutional Network)
- 합성곱 신경망 기초 6(ResNet, Residual Learning for Image Recognition)
- 합성곱 신경망 기초 7(EfficientNet, Rethinking Model Scaling for Convolutional Neural Networks)
- 합성곱 신경망 기초 8(Data Augmentation, 데이터 증강)
가중치 초기화
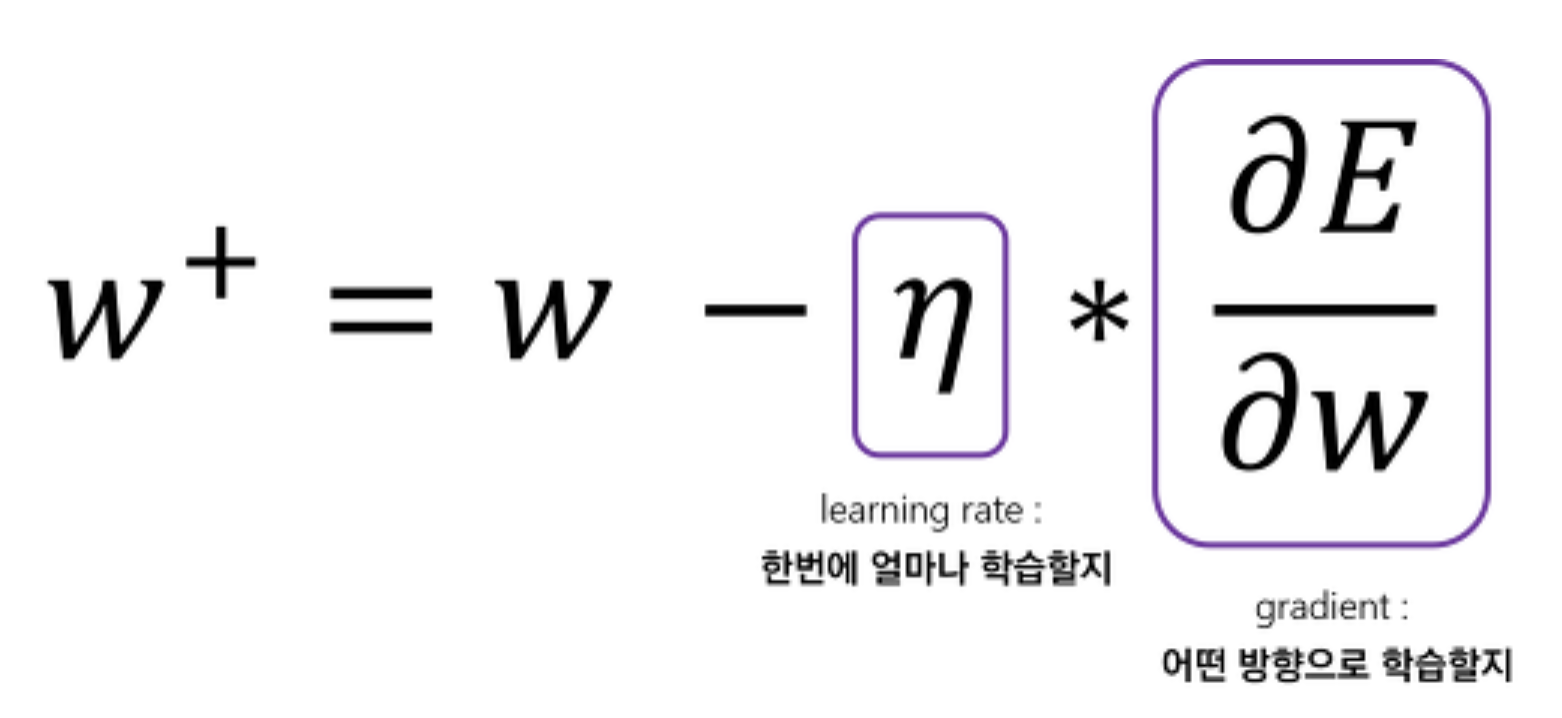
가중치가 중요한 이유
- Overfitting-Underfitting 문제가 발생해 제대로 학습이 되지 않을 수 있다.
- 그래디언트 손실(Vanishing Gradient)와 폭주(Exploding)문제가 발생한다.
- 지역 최적화(Local Optimization)에 실패해 Local mnimum에 수렴하기도 한다.
- 즉, 같은 모델을 훈련시키더라도 가중치가 어떤 초기 값을 갖느냐에 따라서 모델 훈련 결과가 달라진다.
- 가중치 값이 0일 경우, 학습이 불가능하다.
- 가중치 값을 같은 값으로 할 경우, 1개 신경망에 학습시키는 것과 동일
- 평균 0 ,1보다 작은 표준편차 분포를 사용한다.
1) Sigmoid, 정규분포
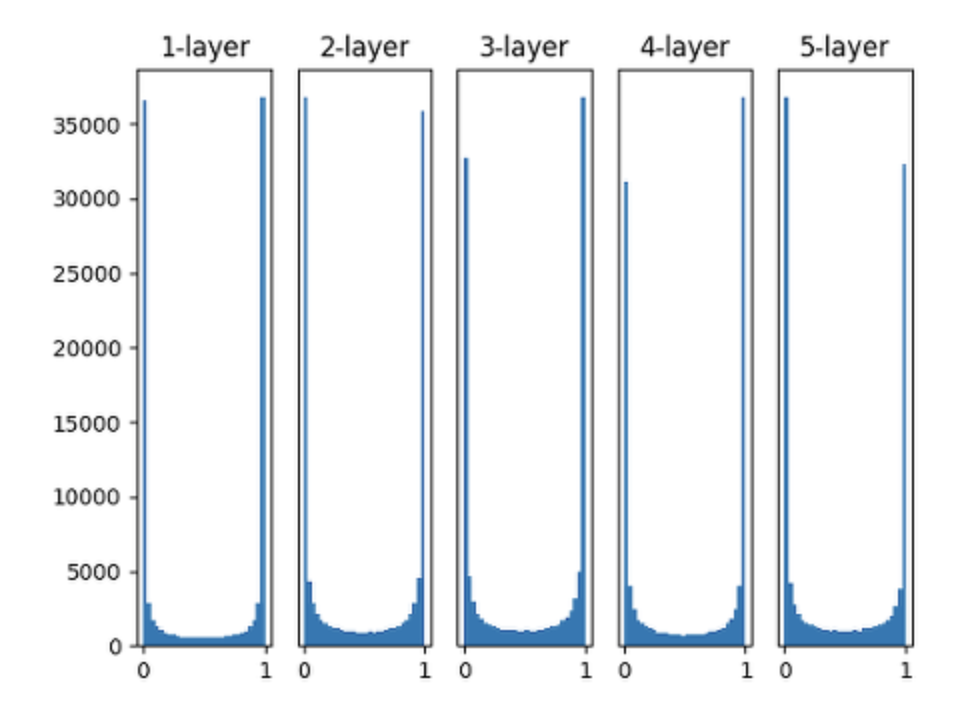
- 표준편차가 크기 때문에 학습이 반복될 수록 0,1로 치우치는 문제가 발생
2) 1)에서 표준편차를 줄였을 경우
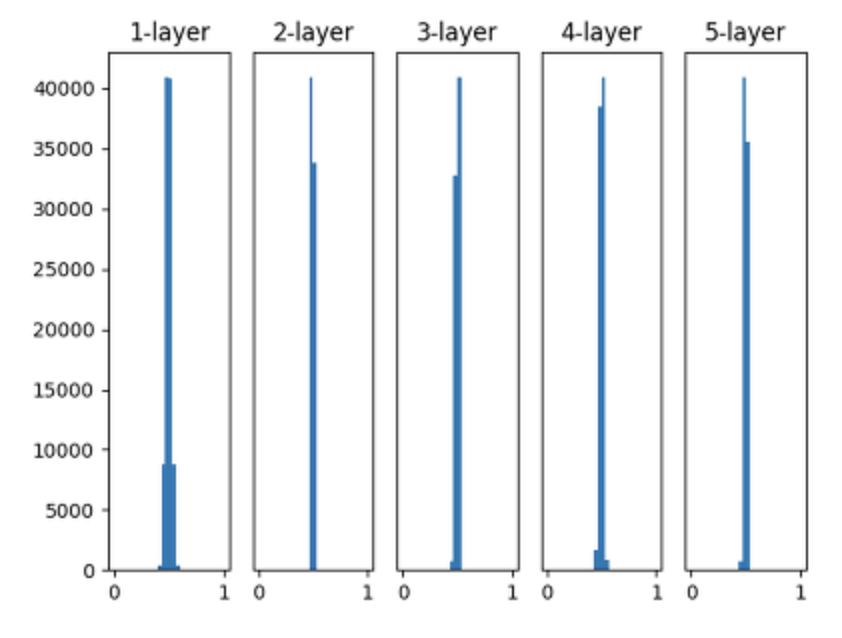
- Sigmoid 그래디언트 최댓값이 0.25이므로 현상을 완화할 수는 있지만 0.5로 몰리는 현상
“더 나은 방법을 찾아보자”
LeCun Initialization
- CNN LeNet 창시자 LeCun이 도입
- 정규분포, Uniform 분포를 따르는 방법 2가지가 있다.

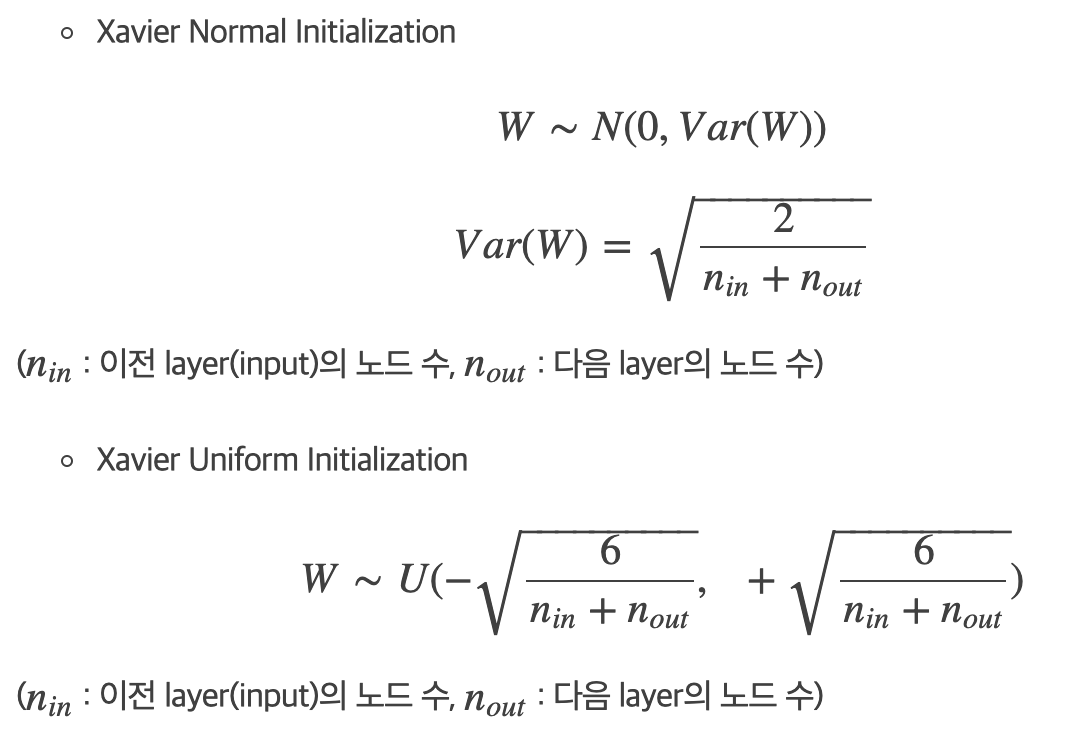
Xavier Initialization
- 이전 노드와 다음 노드 개수에 의존하는 방법
- 비선형함수(ex. sigmoid, tanh)에서 효과적인 결과
He Initialization
- Relu 활성화 함수 사용시, Xavier 설정이 비효율적인 결과를 가져온다.(평균, 표준편차 0으로 수렴)
- 최근 대부분 모델에서 He 초기화를 사용한다.

⭐️ 최근 Deep CNN 모델들은 Gaussian Distribution 초기화 방법 사용
참조 문헌
https://kharshit.github.io/blog/2018/12/28/why-batch-normalization
https://reniew.github.io/13/
https://wooono.tistory.com/227