합성곱 신경망 기초 7(EfficientNet, Rethinking Model Scaling for Convolutional Neural Networks)
CNN 강좌는 여러 절로 구성되어 있습니다.
- 합성곱 신경망 기초(CNN, Convolution Neural Network)
- 합성곱 신경망 기초 2(역전파, Backpropagation)
- 합성곱 신경망 기초 3(배치정규화, Batch Normalization)
- 합성곱 신경망 기초 4(가중치 초기화, Weight Initialization)
- 합성곱 신경망 기초 5(VGGNet, Very Deep Convolutional Network)
- 합성곱 신경망 기초 6(ResNet, Residual Learning for Image Recognition)
- 합성곱 신경망 기초 7(EfficientNet, Rethinking Model Scaling for Convolutional Neural Networks)
- 합성곱 신경망 기초 8(Data Augmentation, 데이터 증강)
EfficientNet
- 2019년 5월에 발표된 이 논문은 한정된 Resource에서 CNN을 깊이와 넓이 그리고 해상도의 밸런스를 조절할 수 있는 새로운 스케일 메소드를 제안
- 최근 CNN Architecture는 효율적인 Mobile-size ConvNet의 디자인이 인기가 많아지고, 수작업으로 만들어진 Mobile ConvNet보다 광범위하게 튜닝 가능한 것이 훨씬 더 나은 퍼포먼스를 도출
- CNN에서의 Network의 깊이와 너비 그리고 이미지의 해상도의 관계를 정량화하여 나타냈다는 점에서 이 논문의 중요한 Key Point
Introduction

-
해상도(Resolution)
- 단순하게, 위 이미지에서 개를 인식한다고 했을 때, 우측처럼 큰 이미지일 수록 인식하기가 쉽다.
- 왜냐하면, 입력의 해상도가 작을수록 CNN을 거치면서 Convolution, Pooling이 진행됨에 따라 특징이 소실되거나, 추출되지 않는 경우가 발생하기 때문이다.
-
깊이(Depth)
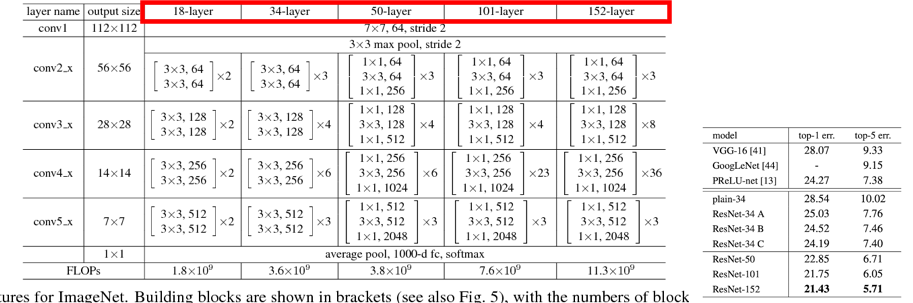
- 이미지의 depth(layer 개수)를 늘릴수록 성능이 증가하는 것은 ResNet의 사례를 통해 알 수 있다.
-
넓이(Channel 개수)
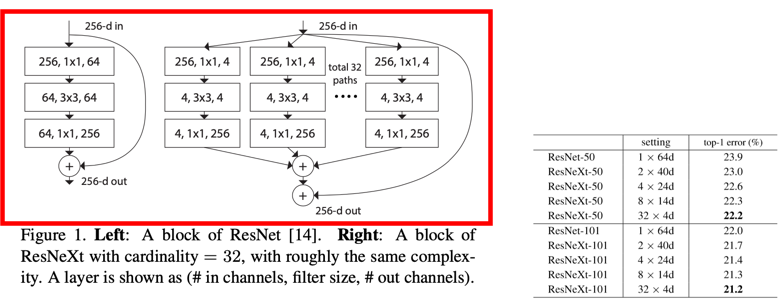
- 네트워크의 넓이(Channel 개수, 혹은 layer 안의 연산)를 늘려서 성능이 좋아진 예시도 ResNet과 ResNext 논문을 비교해보면 알 수 있다.
- ResNext는 네트워크의 한 레이어에서 레이어의 폭을 넓혀 진행한 것을 볼 수 있고, ResNet-50, ResNext-50을 비교했을 때 성능이 향상된 것을 확인할 수 있다.
EfficientNet은 이 점에 착안하여 세 요소들의 균형을 찾기 위한 실험을 진행했다.
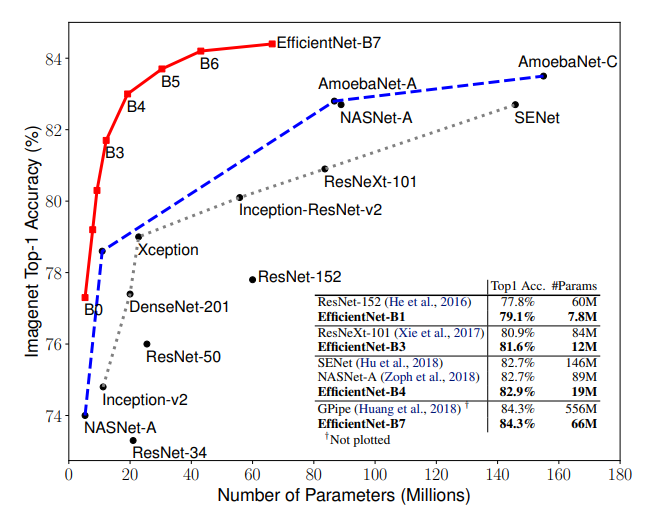
- 기존 Network보다 파라미터 대비 정확도가 높은 효율적인 Network를 제시하였으며 효율적인 Network라는 이름을 본따 EfficientNet으로 정하였다.
- 위 사진을 보면 EfficientNet이 SOTA image classification network보다 효율적인 모델임을 알 수 있다.(B0~B7는 모델 사이즈를 의미)
Compound Model Scaling
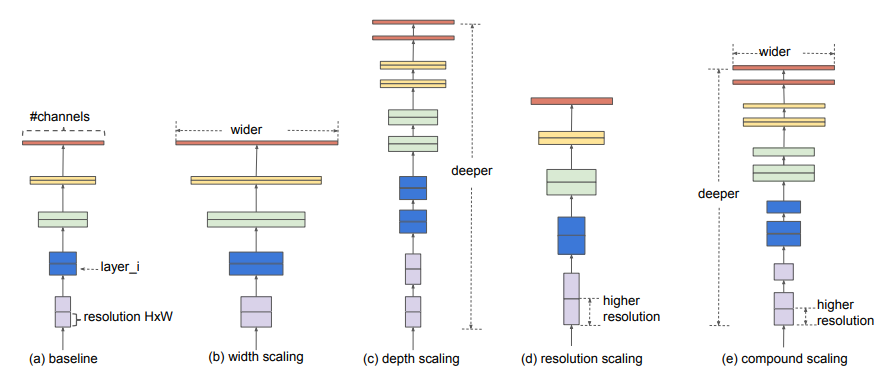
본 논문에서는 어떻게 Network를 확장해야 효율적일지에 대한 연구가 진행되었고 아래에 그림처럼 기본 baseline 모델에서 (b) width (c) depth (d) resolution 관점에서의 scaling을 적절한 비율로 조합한 (e) compound scaling 모델을 제안한다.
-
Depth (d)
- Network가 깊어지면 복잡한 특징을 추출할 수 있고 다른 task에 일반화하기 좋지만 vanishing gradient problem이 생기게 된다.
- 이를 해결하기위해 ResNet의 skip connection, batch normalization 등 다양한 방법들이 있지만 그렇다 하더라도 너무 깊은 Layer를 가진 모델의 성능은 더 좋아지지 않는다.
- Width (w):
- 보통 Width(Channel)는 작은 모델을 만들기 위해 scale down(MobileNet 등)을 하는데에 사용되었다.
- 더 넓은 channel은 더 세밀한 특징을 추출할 수 있고 train하기가 더 쉽다. width의 증가에 따른 성능은 빠르게 saturate되는 현상이 있다.
- Resolution (r)
- 높은 해상도의 이미지를 input으로 사용할때 모델은 더욱 세밀한 패턴을 학습할 수 있기 때문에 성능을 높이기 위해서 Resolution을 크게 가져가고 있다.
- 최근에는 480x480(GPipe) 600x600(object detection)의 size를 사용하고 있다. 하지만 마찬가지로 너무 큰 해상도는 효율적이지 않다.
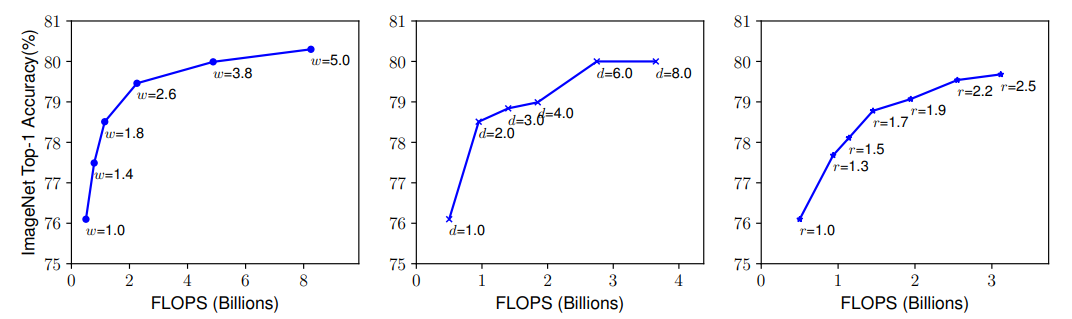
- 위 그래프는 각각 width, depth, resolution을 키웠을 때의 FLOPS(Floating point Operation Per Second)와 Accuracy를 보여준다.
- width, depth, resolution 모두 80% accuracy까지만 빠르게 saturate(포화)되고 그 이후로의 성능향상은 한계가 있을을 알 수 있다.
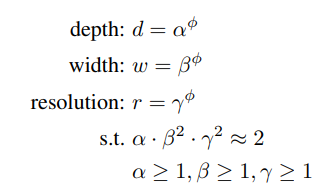
- 먼저 depth를 α, width를 β, resolution을 γ로 만들고 ϕ=1 일때의 α x β^2 x γ^2 ≈ 2를 만족하는 α, β, γ를 grid search를 통해 찾는다. (논문에서 찾은 값은 α=1.2, β=1.1, γ=1.15 이다.)
- 여기서 width와 resolution에 제곱항이 있는 이유는 depth(Layer)가 2배 증가하면 FLOPS는 2배가 되지만 width와 resolution은 그렇지 않기 때문이다.
- width는 이전 레이어의 출력, 현재 레이어의 입력 이렇게 두곳에서 연산이 이루어 지므로 width가 2배가 되면 4배의 FLOPS가 된다.
- resolution은 가로 x세로 이기 때문에 당연히 resolution이 2배가 되면 4배의 FLOPS가 된다.
- grid search를 통해 α, β, γ를 찾았다면 ϕ(0, 0.5, 1, 2, 3, 4, 5, 6)를 사용해 최종적으로 기존 width, depth, resolution에 곱할 factor를 만들게 된다.(파이의 변화로 B0~B7까지의 모델을 설계하였음)
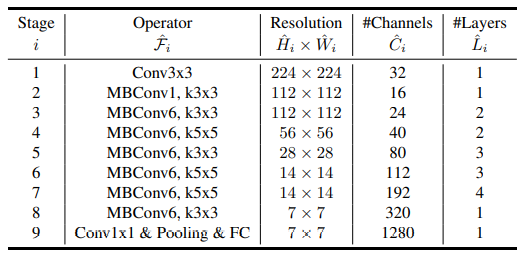
- 위 그림은 scaling을 하지 않은 기본 B0모델 구조이다. Operator의 MBConv는 Mobilenet v2에서 제안된 inverted residual block을 의미하고 바로 옆에 1 혹은 6은 expand ratio이다.
- ImageNet dataset의 size인 224x224를 input size로 사용하였다.
- Activation function으로 ReLU가 아닌 Swish(혹은 SiLU(Sigmoid Linear Unit))를 사용하였다. Swish 는 매우 깊은 신경망에서 ReLU 보다 높은 정확도를 달성한다고 알려져있다. squeeze-and-excitation optimization 사용
squeeze-and-excitation optimization
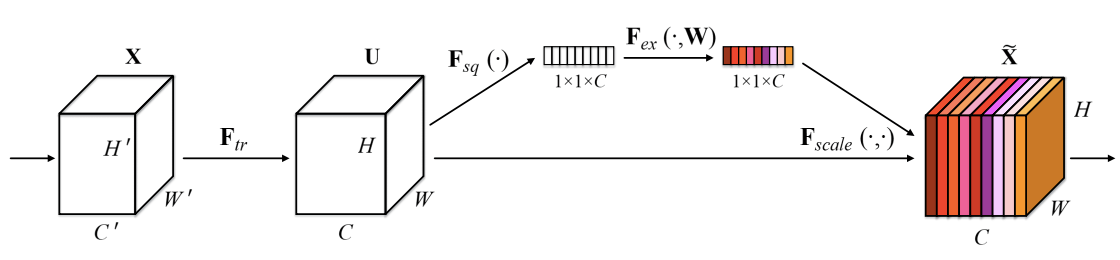
- Squeeze? pooling을 통해 1x1 size로 줄여서 정보를 압축한 뒤에 excitation 즉 압축된 정보들을 weighted layer와 비선형 activation function으로 각 채널별 중요도를 계산하여 기존 input에 곱을 해주는 방식
Experiments
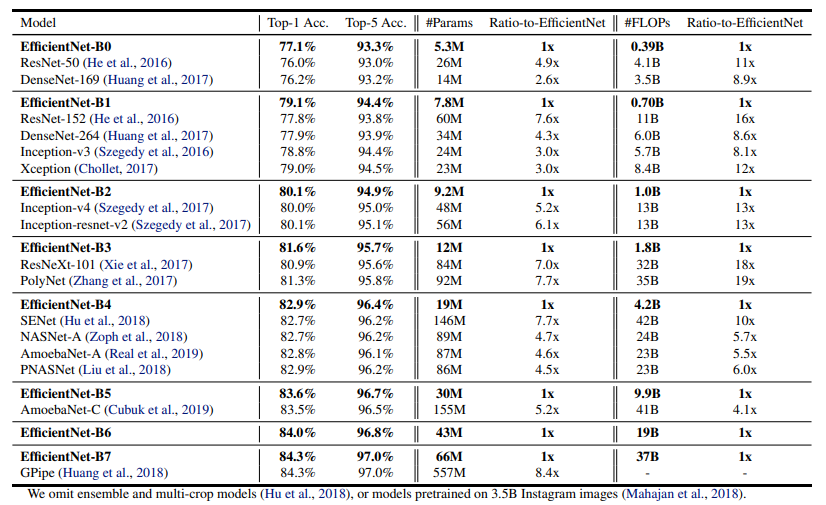
- 비슷한 Top-1, Top-5 Accuracy를 보이는 기존의 ConvNet들을 묶어 EfficientNet과 비교한 것이다.
- 모든 영역에서 일관되게 EfficientNet이 훨씬 적은 parameter 수와 FLOPS를 보여주는 것을 알 수 있다.
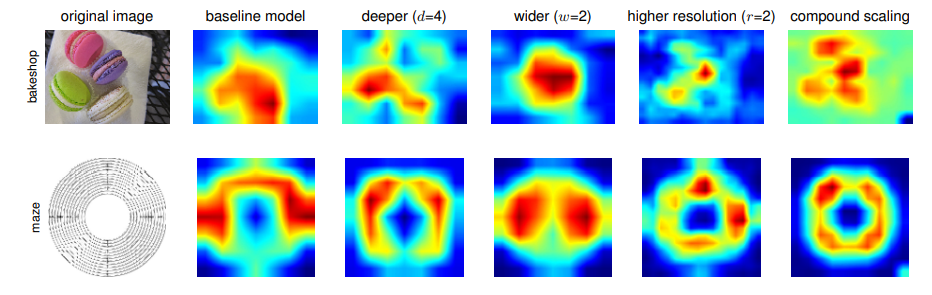
다음은 Class Activation Map(CAM)을 Network의 depth, width, resolution만 조정하여 설계하였을 때와 compound scaling을 활용하여 균형을 맞췄을 때의 CAM 비교 결과이다.
참조 문헌
[1]
https://hoya012.github.io/blog/EfficientNet-review/
[2]
https://www.youtube.com/watch?v=Vhz0quyvR7I&feature=youtu.be