합성곱 신경망 기초 8(데이터 증강, Data Augmentation)
CNN 강좌는 여러 절로 구성되어 있습니다.
- 합성곱 신경망 기초(CNN, Convolution Neural Network)
- 합성곱 신경망 기초 2(역전파, Backpropagation)
- 합성곱 신경망 기초 3(배치정규화, Batch Normalization)
- 합성곱 신경망 기초 4(가중치 초기화, Weight Initialization)
- 합성곱 신경망 기초 5(VGGNet, Very Deep Convolutional Network)
- 합성곱 신경망 기초 6(ResNet, Residual Learning for Image Recognition)
- 합성곱 신경망 기초 7(EfficientNet, Rethinking Model Scaling for Convolutional Neural Networks)
- 합성곱 신경망 기초 8(Data Augmentation, 데이터 증강)
Data Augmentation이란?

- Data Augmentation은 데이터의 양을 늘리기 위해 원본에 각종 변환을 적용하여 충분히 학습에 활용될 수 있는 데이터 개수를 증강시키는 기법이다.
- CNN은 영상의 2차원 변환인 회전(Rotation), 크기(Scale), 밀림(Shearing), 반사(Reflection), 이동(Translation)와 같은 2차원 변환인 Affine Transform에 취약하다.
- 즉, Affine Tranform으로 변환된 영상은 다른 영상으로 인식한다.
- 또한 Noise삽입, 색상, 밝기 변형 등을 활용하여 Data Augmentation 효과를 얻을 수 있다.
어떻게 Data Augumentation이 나왔을까?
-
Augmenation 기술은 사실 많이 활용되던 기술이 아니다. 이는 알고리즘적인 해결방법이 아니라, 순수한 공학적 접근을 통한 추론을 위한 전처리 기술 중 하나였다.
- 딥러닝의 고질적인 문제는 여러가지 있는데, 그 중 대표적인 문제가 Overfitting이다. 과거 Overfitting을 해결하기 위해 익히 알고있는 모델링 수정 Regularization, Normalization을 활용했다.
- 하지만, 이와 같은 Overfitting을 해결 방법은 편향 학습 방향을 조금 죽이는 정도다. 따라서 결과적으로 우리가 원하는 Overfitting을 해결하는 기술이 되진 않았다.
👉 공학적 방법으로 학습의 방향성을 상하좌우 더 넓힐 수 있는 방법이 없을지 고민하게 된다. 단순히 편향된 학습은 오류를 발생시키지만,여기서의 목적은 적당한 힘으로 학습을 아주 조금 골고루 넓히자는 의미이다.
방법론에는 Image Manipulation, Generative Model,AutoML 기반 방법론 등 다양한게 있지만 주요 방법론인 Image Manipulation 기반을 살펴보자.
Image Manipulation 기반 방법론
Pixel-Level Transforms

- 우선 Pixel 단위로 변환을 시키는 Pixel-Level Transform은 대표적으로 Blur, Jitter, Noise 등을 이미지에 적용하는 기법이다.
- Gaussian Blur, Motion Blur, Brightness Jitter, Contrast Jitter, Saturation Jitter, ISO Noise, JPEG Compression 등 다양한 기법이 사용된다.
Spatial-Level Transforms

- Image 자체를 변화시키는 Spatial-Level Transform으로, 대표적으로 Flip과 Rotation이 있으며, Image의 일부 영역을 잘라내는 Crop도 많이 사용한다.
- 주의해야할 점은 Detection (Bounding Box), Segmentation (Mask) Task의 경우 Image에 적용한 Transform을 GT에도 동일하게 적용을 해줘야 하고, Classification의 경우 적용하였을 때 Class 가 바뀔 수 있음을 고려하여 적용해야 한다. (Ex, 6을 180도 회전하면 9)
“MixUp: Beyond Empirical Risk Minimization”, 2018
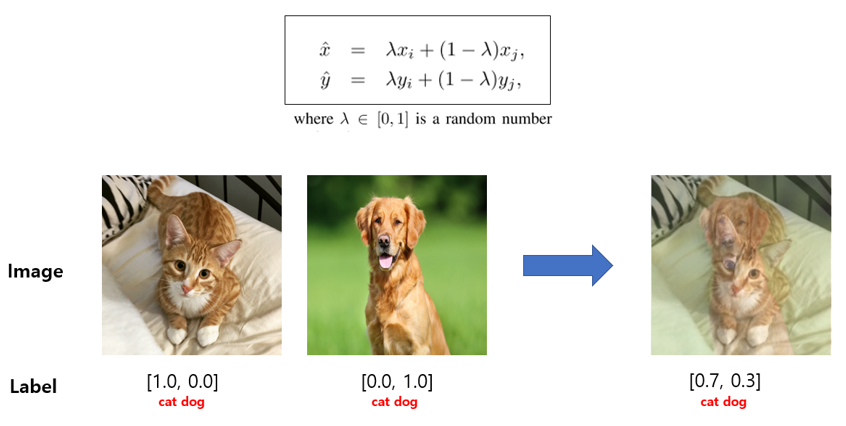
- 두 image와 Label을 0~1 사이의 lambda 값을 통해 Weighted Linear Interpolation 해주는 기법이다.
- 보통 lambda 값은 beta distribution을 통해 뽑아낸다. 이 방법은 굉장히 단순하지만 모델의 일반화 성능도 좋아지고 corrupt label의 memorization을 방지해주고, adversarial example에 sensitive해지는 등 다양한 효과를 얻을 수 있다.
“CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features”, 2019

- 우리 나라 연구 성과인 CutMix, MixUp은 두 image를 섞는 방식이고, Cutout은 image의 box를 쳐서 지우는 방식이었다면, CutMix는 두 방법을 합친 방법이다.
- 이미지 데이터를 Convex combination하여 새로운 데이터를 만드는 것으로 클래스가 다른 이미지들도 mixup하여 label 또한 mixup을 한다는 것이다.
- 원본 image에서 box를 쳐서 지운 다음 그 빈 영역을 다른 image로부터 patch를 추출하여 집어넣는다. Patch의 면적에 비례하여 Label도 섞어주는 방식이다.
- 이 방법을 적용하면 실제로 데이터 모델링시 성능이 많이 좋아지는 경우가 많다고 한다.
결론
- Data augmentation의 경우 over fitting을 방지하기 위한 여러 기술 중 하나로 발전되고 있다.
- Over fitting은 알고리즘의 Variance가 클 때 발생하는 문제로, train data set에 대해 learning을 정상적으로 마친 후 test data set에 적용할 때 그 결과가 매우 다르게 나온다는 것을 의미한다.
- 이러한 Over fitting을 방지하기 위해 Variance를 낮추는 방법으로는 training data를 많이 모으는 방법, feature의 개수를 줄이는 방법, regularization을 통해 weight 값을 조절해주는 방법 등이 있다.
- 여기에서 training data를 많이 모으는 방법은 금전적, 시간적으로 손실이 큰데, 이를 해결하기 위한 기존에 있는 Data를 활용하여 변형하는 방법이 Data augmentation이다.
참조 문헌
[1] A survey on Image Data Augmentation for Deep Learning, 2019
https://journalofbigdata.springeropen.com/articles/10.1186/s40537-019-0197-0